Updating Customer Data Without the Prisma Campaigns Unique Identifier
When you need to update customer data based on a .csv file from an independent source, you can map it to the internal database using the Prisma Campaigns unique identifier or a common field. This way, you can use it when setting up a data synchronization. Email addresses, social security numbers or any other field with similar characteristics allow you to associate an individual or group of people between those two unrelated systems.
To create a data synchronization that uses a field other than the Prisma Campaigns unique identifier, follow these steps:
-
Go to Settings and click the Column Mappings menu.
-
Hit New Column Mapping and then choose Add Import.
-
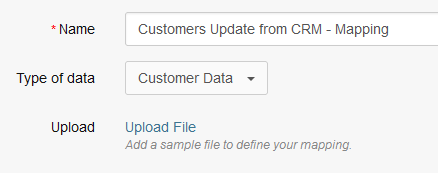
Enter a descriptive name, select the type (Customer Data in this case) from the list and upload the .csv file from the external system.
-
Enable the Use a field other than Customer Identifier switch.
-
Pick the field in the File Column dropdown list and its Prisma Campaigns column match (email and Email address in this case, respectively). Optionally, you can select a strategy for when no matching customer is found (reject row by default):
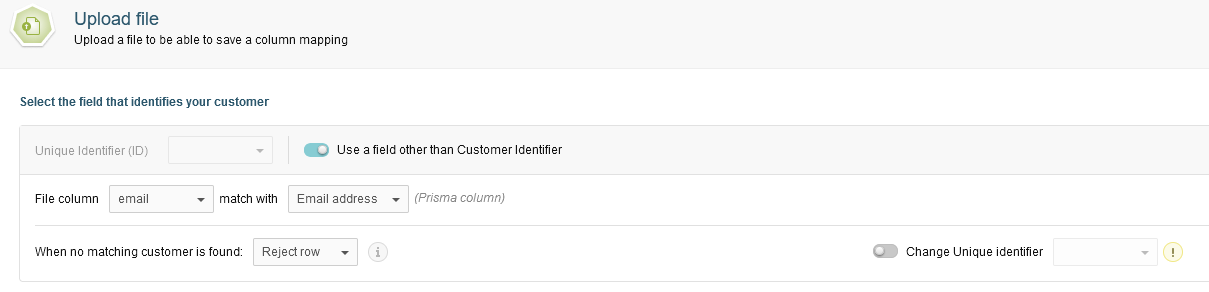
You can change the Prisma Campaigns unique identifier in this operation. However, doing so resets all past interactions with any matching customers and will affect the customer journey timeline. Only conversions, opt-outs and dismisses will persist.
-
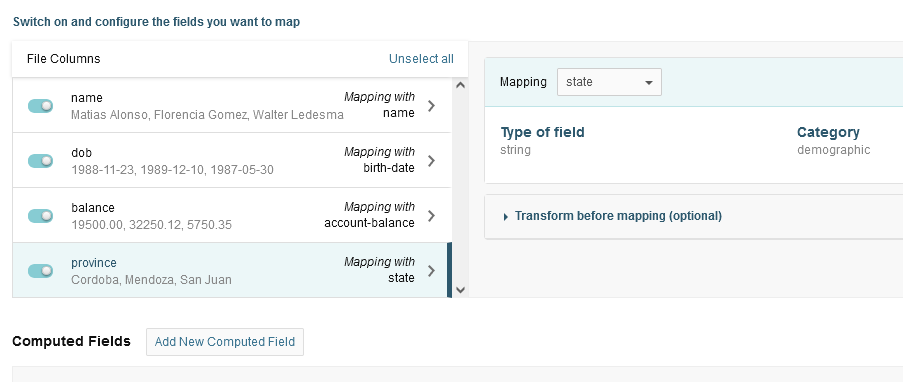
Select the rest of the relevant columns from the file, map them with the corresponding fields in the Prisma Campaigns customer model, and click Add Mapping. Note that at this point you can transform data as illustrated in the Available Transformations section of the user manual or create new calculated fields based on the file’s contents.
Once you have finished mapping the columns, do not forget to save the column mapping:
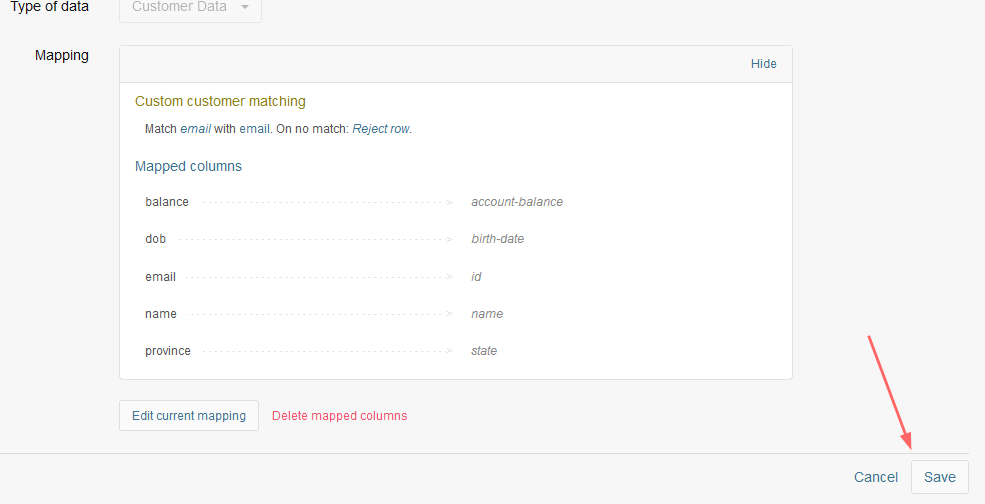
All data syncs that use this column mapping will update the pertinent customers based on the identifier that you chose.